 Access
Access Analyze
Analyze Develop
Develop About
About
TRanscriptome User-Friendly Analysis (TRUFA)Application of next-generation sequencing (NGS) methods for transcriptome analysis (RNA-seq) has become increasingly accessible in recent years and are of great interest to many biological disciplines including e.g., evolutionary biology, ecology, biomedicine, and computational biology. Although virtually any research group can now obtain RNA-seq data, only a few have the bioinformatics knowledge and computation facilities required for transcriptome analysis. TRUFA (TRanscriptome User-Friendly Analysis) is an open informatics platform offering a web-based interface that generates the outputs commonly used in de novo RNA-seq analysis and comparative transcriptomics. TRUFA provides a comprehensive service that allows performing dynamically raw read cleaning, transcript assembly, annotation, and expression quantification. Due to the computationally intensive nature of such analyses, TRUFA is highly parallellized and benefits from accessing high-performance computing resources. |
|
The complete TRUFA pipeline was validated using four previously published transcriptomic data sets. TRUFA's results for the example datasets showed globally similar results when comparing with the original studies, and performed particularly better when analyzing the green tea dataset. The platform permits analyzing RNA-seq data in a fast, robust, and user-friendly manner. Currently accounts on TRUFA are provided freely upon request at https://trufa.ifca.es. TRUFA has been developed by IFCA in collaboration with MNCN (Spanish Natural Science Museum, also in CSIC). Access to the web portal is available under subscription for the research community.
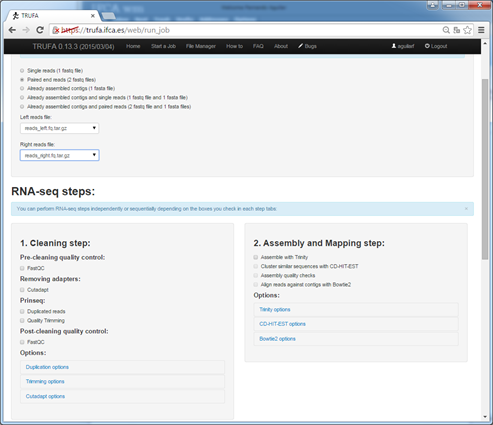
After registration, user have to upload input files to be analyzed. Different formats are allowed. A form has to be filled in order to configure the pipeline of the workflow and then the needed jobs will be submitted. User can get information about the status of the execution and get the output once all the workflow has finished. For further information please access to the « How to » web page.
- INDIGO-DataCloud: As case study.
The portal has been developed in Python basically, and it is divided in three layers :
- The top layer is the web interface that allows users to access, manage the input files, launch new analysis, check the output files, etc. It is made in Python and other technologies such as JavaScript, sqlite or php.
- The second layer is the pipeline system that configure the list of jobs to be submitted and it is also made in python.
- The last layer is the computing one, that is currently deployed in the Altamira Supercomputer. Includes a batch system that allows the layers above to get information about the job status.